Common Lispのランダムフォレストライブラリcl-random-forestで特徴量の重要度を出してみる
(Lisp Advent Calendar 2017参加記事)
概要
ランダムフォレストは多くの特徴量を持つような大きなサイズのデータセットを現実的な計算量で学習できる便利なモデルであるが、その重要な特徴の一つに、「特徴量ごとの重要度を推測できる」というものがある。
特徴量の重要度の推測の方法にも色々あるが、これらの記事では、MeanDecreaseAccuracyとMeanDecreaseGiniという2つの方法が紹介されている。それぞれ、
- バギングの際に決定木ごとの除外されたデータ(Out-Of-Bagデータ; OOBデータ)を特徴量ごとにシャッフルし、元のOOBデータを予測したときの正答率に対して特徴量ごとにシャッフルしたデータでどれだけ正答率が悪化するかを森全体で調べ、平均する
- 決定木の枝の分岐は、それによって新たに分割される領域の不純度(分類の場合はエントロピーあるいはジニ係数。回帰であれば分散を使う)が分割前よりも下がるように選ばれる。森全体で特徴量ごとに不純度の低下量の平均値を出す
というもの。詳しくは上記記事を見てほしい。
この2つをCommon Lispによるランダムフォレストの実装cl-random-forestに組み込んでみた。
UCIのAdultデータセットを予測する
まずは分類問題の例としてよく使われるAdultデータセットを読み込んでみる。 これはアメリカの国勢調査を元にしたデータで、年齢や学歴、職業など14の特徴量から年収が5万ドルを越えるかどうかを予測する。
データは以下のようなCSVファイルになっている。
wiz@prime:~/datasets$ head adult.data
39, State-gov, 77516, Bachelors, 13, Never-married, Adm-clerical, Not-in-family, White, Male, 2174, 0, 40, United-States, <=50K
50, Self-emp-not-inc, 83311, Bachelors, 13, Married-civ-spouse, Exec-managerial, Husband, White, Male, 0, 0, 13, United-States, <=50K
38, Private, 215646, HS-grad, 9, Divorced, Handlers-cleaners, Not-in-family, White, Male, 0, 0, 40, United-States, <=50K
53, Private, 234721, 11th, 7, Married-civ-spouse, Handlers-cleaners, Husband, Black, Male, 0, 0, 40, United-States, <=50K
28, Private, 338409, Bachelors, 13, Married-civ-spouse, Prof-specialty, Wife, Black, Female, 0, 0, 40, Cuba, <=50K
37, Private, 284582, Masters, 14, Married-civ-spouse, Exec-managerial, Wife, White, Female, 0, 0, 40, United-States, <=50K
49, Private, 160187, 9th, 5, Married-spouse-absent, Other-service, Not-in-family, Black, Female, 0, 0, 16, Jamaica, <=50K
52, Self-emp-not-inc, 209642, HS-grad, 9, Married-civ-spouse, Exec-managerial, Husband, White, Male, 0, 0, 45, United-States, >50K
31, Private, 45781, Masters, 14, Never-married, Prof-specialty, Not-in-family, White, Female, 14084, 0, 50, United-States, >50K
42, Private, 159449, Bachelors, 13, Married-civ-spouse, Exec-managerial, Husband, White, Male, 5178, 0, 40, United-States, >50K
LIBSVM形式への変換
まずは、これをLIBSVMのデータ形式に変換してファイル出力しておく。こうしておけば別のツールで分析するときにも使える。
数値の特徴はそのままparse-integerして、カテゴリの特徴はリスト中のポジションを返すようにする。さらに、たまに欠損値があるので、そのデータは飛ばすようにする。
(ql:quickload :fare-csv)
(ql:quickload :anaphora)
(defparameter *workclass*
'("Private" "Self-emp-not-inc" "Self-emp-inc" "Federal-gov" "Local-gov" "State-gov"
"Without-pay" "Never-worked"))
(defparameter *education*
'("Bachelors" "Some-college" "11th" "HS-grad" "Prof-school" "Assoc-acdm" "Assoc-voc"
"9th" "7th-8th" "12th" "Masters" "1st-4th" "10th" "Doctorate" "5th-6th" "Preschoo"))
(defparameter *marital-status*
'("Married-civ-spouse" "Divorced" "Never-married" "Separated" "Widowed"
"Married-spouse-absent" "Married-AF-spouse"))
(defparameter *occupation*
'("Tech-support" "Craft-repair" "Other-service" "Sales" "Exec-managerial" "Prof-specialty"
"Handlers-cleaners" "Machine-op-inspct" "Adm-clerical" "Farming-fishing" "Transport-moving"
"Priv-house-serv" "Protective-serv" "Armed-Forces"))
(defparameter *relationship*
'("Wife" "Own-child" "Husband" "Not-in-family" "Other-relative" "Unmarried"))
(defparameter *race*
'("White" "Asian-Pac-Islander" "Amer-Indian-Eskimo" "Other" "Black"))
(defparameter *sex*
'("Female" "Male"))
(defparameter *native-country*
'("United-States" "Cambodia" "England" "Puerto-Rico" "Canada" "Germany" "Outlying-US(Guam-USVI-etc)"
"India" "Japan" "Greece" "South" "China" "Cuba" "Iran" "Honduras" "Philippines" "Italy" "Poland"
"Jamaica" "Vietnam" "Mexico" "Portugal" "Ireland" "France" "Dominican-Republic" "Laos" "Ecuador"
"Taiwan" "Haiti" "Columbia" "Hungary" "Guatemala" "Nicaragua" "Scotland" "Thailand" "Yugoslavia"
"El-Salvador" "Trinadad&Tobago" "Peru" "Hong" "Holand-Netherlands"))
(defparameter *attr-tables*
(list nil *workclass* nil *education* nil *marital-status* *occupation* *relationship*
*race* *sex* nil nil nil *native-country*))
(defun convert-libsvm-line (data-lst)
(flet ((pos (lst str) (position str lst :test #'string=)))
(let* ((label (if (string= ">50K" (car (last data-lst))) "1" "-1"))
(data (subseq data-lst 0 (1- (length data-lst))))
(data-num (mapcar (lambda (data-elem attr-table)
(if (null attr-table)
(parse-integer data-elem)
(pos attr-table data-elem)))
data
*attr-tables*))
(data-num-str-lst (loop for i from 1
for n in data-num
collect (format nil " ~A:~A" i n))))
(if (not (some #'null data-num)) ; cut out the line which has nil element
(apply #'concatenate 'string label data-num-str-lst)))))
(defun convert-libsvm (in-file out-file)
(with-open-file (in in-file)
(with-open-file (out out-file :direction :output :if-exists :supersede)
(let ((read-data (fare-csv:read-csv-line in)))
(loop while read-data do
(anaphora:aif (convert-libsvm-line read-data)
(format out "~A~%" anaphora:it))
(setf read-data (fare-csv:read-csv-line in)))))))
(convert-libsvm "/home/wiz/datasets/adult.data" "/home/wiz/datasets/adult.libsvm")
変換後のデータはこうなっている。行頭の要素がターゲットの値で、残りが各特徴のインデックスと入力値を:でつないだペアのリストになる。疎なデータを扱うのに向いている形式になっている。
wiz@prime:~/datasets$ head adult.libsvm
-1 1:39 2:5 3:77516 4:0 5:13 6:2 7:8 8:3 9:0 10:1 11:2174 12:0 13:40 14:0
-1 1:50 2:1 3:83311 4:0 5:13 6:0 7:4 8:2 9:0 10:1 11:0 12:0 13:13 14:0
-1 1:38 2:0 3:215646 4:3 5:9 6:1 7:6 8:3 9:0 10:1 11:0 12:0 13:40 14:0
-1 1:53 2:0 3:234721 4:2 5:7 6:0 7:6 8:2 9:4 10:1 11:0 12:0 13:40 14:0
-1 1:28 2:0 3:338409 4:0 5:13 6:0 7:5 8:0 9:4 10:0 11:0 12:0 13:40 14:12
-1 1:37 2:0 3:284582 4:10 5:14 6:0 7:4 8:0 9:0 10:0 11:0 12:0 13:40 14:0
-1 1:49 2:0 3:160187 4:7 5:5 6:5 7:2 8:3 9:4 10:0 11:0 12:0 13:16 14:18
1 1:52 2:1 3:209642 4:3 5:9 6:0 7:4 8:2 9:0 10:1 11:0 12:0 13:45 14:0
1 1:31 2:0 3:45781 4:10 5:14 6:2 7:5 8:3 9:0 10:0 11:14084 12:0 13:50 14:0
1 1:42 2:0 3:159449 4:0 5:13 6:0 7:4 8:2 9:0 10:1 11:5178 12:0 13:40 14:0
さらに、行の順番をシャッフルして、30117行のうち最初の28000行を訓練データ、残りをテストデータとして分割しておく。
shuf adult.libsvm > adult.libsvm.shuf
split -l 28000 adult.libsvm.shuf adult.libsvm.shuf.split.
mv adult.libsvm.shuf.split.aa adult.libsvm.train
mv adult.libsvm.shuf.split.ab adult.libsvm.test
ランダムフォレストを構築
次に、cl-random-forestでLIBSVM形式のデータを読み込み、ランダムフォレストを構築する。テストデータに対して予測を行うと正答率は86.8%くらい出ることが分かる。
(ql:quickload :cl-random-forest)
(in-package :clrf)
(defparameter *adult-dim* 14)
(defparameter *adult-n-class* 2)
;; Load dataset
(let ((adult-train (clol.utils:read-data "/home/wiz/datasets/adult.libsvm.train" *adult-dim*))
(adult-test (clol.utils:read-data "/home/wiz/datasets/adult.libsvm.test" *adult-dim*)))
(dolist (datum adult-train)
(if (> (car datum) 0d0)
(setf (car datum) 0)
(setf (car datum) 1)))
(dolist (datum adult-test)
(if (> (car datum) 0d0)
(setf (car datum) 0)
(setf (car datum) 1)))
(multiple-value-bind (datamat target)
(clol-dataset->datamatrix/target adult-train)
(defparameter *adult-datamatrix* datamat)
(defparameter *adult-target* target))
(multiple-value-bind (datamat target)
(clol-dataset->datamatrix/target adult-test)
(defparameter *adult-datamatrix-test* datamat)
(defparameter *adult-target-test* target)))
;; Training
(setf lparallel:*kernel* (lparallel:make-kernel 4)) ; Enable parallelization
(defparameter *adult-forest*
(make-forest *adult-n-class* *adult-datamatrix* *adult-target*
:n-tree 100 :bagging-ratio 0.9 :max-depth 15 :n-trial 28 :min-region-samples 5
:remove-sample-indices? nil))
(test-forest *adult-forest* *adult-datamatrix-test* *adult-target-test*)
;; Accuracy: 86.773735%, Correct: 1837, Total: 2117
ランダムフォレストから特徴量の重要度を出す
さて、ランダムフォレストのモデルができたので、そこから特徴量の重要度を計算できる。特徴量ごとにデータをシャッフルし正答率の低下を見るには、forest-feature-importance関数を使う。これは特徴量ごとにランダムフォレスト中の決定木の全てを使ってOOBデータをテストするのでかなり重い。
一方、不純度の低下量の平均を見る方式ではforest-feature-importance-impurity関数を使う。こちらは構築済みのモデルに必要な情報が全部入っているので、データを使ってテストする必要がなく、計算はとても軽いが、実際にデータを使って正答率への影響を調べている分、前者の方が信頼性はたぶん高い。
なお重要度は各特徴量間の相対的な指標なので、全体の和が1になるように正規化してある。
;; Mean Decrease Accuracy
(forest-feature-importance *adult-forest* *adult-datamatrix* *adult-target*)
;; #(0.06574301 0.02194477 0.0051479316 0.01906538 0.18420668 0.25212014
;; 0.060366035 0.08803416 0.005721473 0.03548798 0.17484868 0.045632493
;; 0.03855448 0.0031268573)
;; Mean Decrease Entropy
(forest-feature-importance-impurity *adult-forest*)
;; #(0.07758663559857257d0 0.08878211431438537d0 0.10551577674479538d0
;; 0.05869010967361182d0 0.05507325082290451d0 0.07511676066651246d0
;; 0.06875969568617234d0 0.07264544881317599d0 0.03029369374727558d0
;; 0.04594328416741256d0 0.1171034605055713d0 0.10565672322170046d0
;; 0.06781795770483026d0 0.031015088333079505d0)
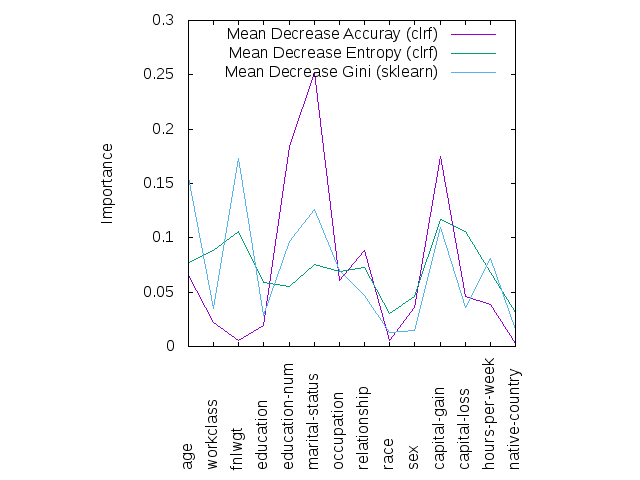
この結果をプロットしてみるとこうなる。どの方法でもピークは一致している雰囲気がないでもない。年収の大小を予測するに当たって、就学年数や結婚歴、キャピタルゲインが重要そうであるということが分かった。
番外: scikit-learnの場合
scikit-learnではデフォルトではジニ係数による不純度低下によって特徴量の重要度を出しているらしい。プロットを見てもエントロピーによる不純度低下と似たような形になった。LIBSVM形式のデータはload_svmlight_fileパッケージを使えば簡単に読み込める。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_svmlight_file
import os
os.chdir(os.path.join(os.path.expanduser("~"), "datasets"))
X_train, y_train = load_svmlight_file("adult.libsvm.train", n_features=14)
X_test, y_test = load_svmlight_file("adult.libsvm.test", n_features=14)
clf = RandomForestClassifier(n_estimators=100, n_jobs=4)
clf = clf.fit(X_train, y_train)
clf.score(X_test, y_test)
importances = clf.feature_importances_
# >>> importances
# array([ 0.15577507, 0.03496241, 0.17293515, 0.02836921, 0.09693498,
# 0.12585869, 0.06974428, 0.04656888, 0.01267463, 0.01457374,
# 0.10987419, 0.03547976, 0.08083613, 0.0154129 ])
メモ: 上の図の作り方
X軸の目盛りに文字列を表示するのに手間取ったのでメモしておく。
clgplotという自作のGnuplotのフロントエンドを使っている。
(ql:quickload :clgplot)
(clgp:plots
(list #(0.06574301 0.02194477 0.0051479316 0.01906538 0.18420668 0.25212014
0.060366035 0.08803416 0.005721473 0.03548798 0.17484868 0.045632493
0.03855448 0.0031268573)
#(0.07758663559857257d0 0.08878211431438537d0 0.10551577674479538d0
0.05869010967361182d0 0.05507325082290451d0 0.07511676066651246d0
0.06875969568617234d0 0.07264544881317599d0 0.03029369374727558d0
0.04594328416741256d0 0.1171034605055713d0 0.10565672322170046d0
0.06781795770483026d0 0.031015088333079505d0)
#(0.15577507 0.03496241 0.17293515 0.02836921 0.09693498
0.12585869 0.06974428 0.04656888 0.01267463 0.01457374
0.10987419 0.03547976 0.08083613 0.0154129))
:title-list '("Mean Decrease Accuray (cl-random-forest)"
"Mean Decrease Entropy (cl-random-forest)"
"Mean Decrease Gini (scikit-learn)")
:y-label "Importance"
:output "/home/wiz/tmp/adult-feature-importance.png")
clgplotは/tmp以下にgnuplotのデータファイル/tmp/clgplot-tmp.dat.Xとスクリプトファイル/tmp/clgplot-tmp.gpを生成する。
set term png
set output "/home/wiz/tmp/adult-feature-importance.png"
set ylabel "Importance"
set xrange []
set yrange []
set size ratio 1.0
set xtics rotate by 90 offset 0,-6
set xtics ('age' 0, 'workclass' 1, 'fnlwgt' 2, 'education' 3, 'education-num' 4, 'marital-status' 5, 'occupation' 6, 'relationship' 7, 'race' 8, 'sex' 9, 'capital-gain' 10, 'capital-loss' 11, 'hours-per-week' 12, 'native-country' 13)
set bmargin 7
plot "/tmp/clgplot-tmp.dat.0" using 1:2 with lines title "Mean Decrease Accuray (clrf)" axis x1y1, \
"/tmp/clgplot-tmp.dat.1" using 1:2 with lines title "Mean Decrease Entropy (clrf)" axis x1y1, \
"/tmp/clgplot-tmp.dat.2" using 1:2 with lines title "Mean Decrease Gini (sklearn)" axis x1y1
生成された.gpファイルにxticsとbmarginの設定を手動で加えた。まずbmarginでグラフの下に空間を作る。xticsでX軸の目盛りに文字列を付けることができる。ここで文字列が横書きだと全部オーバーラップしてしまって読めないので、反時計周りに90度傾けるようにxtics rotate by 90を指定した。さらに、このままだとグラフにめり込むので、文字列の開始位置を下にずらすようにxtics rotate by 90 offset 0,-6とした。