cl-random-forestでクロスバリデーション
11 July 2017
kaggleに登録してみたのでとりあえずDigit Recognizerをやってみた。このデータセットではテストデータにはラベルが付いてなくて、予測結果を投稿して初めてテストデータに対する正答率が分かる。ので、学習のメタパラメータのチューニングは訓練データでクロスバリデーションすることによって決める。
cl-random-forestにn-foldクロスバリデーションを実装したのでMNISTで試してみる。データセットの分割数を5とすると、
(ql:quickload :cl-random-forest)
;; MNISTのデータを用意する
(defparameter mnist-dim 780)
(defparameter mnist-n-class 10)
(let ((mnist-train (clol.utils:read-data "/home/wiz/tmp/mnist.scale" mnist-dim :multiclass-p t))
(mnist-test (clol.utils:read-data "/home/wiz/tmp/mnist.scale.t" mnist-dim :multiclass-p t)))
;; Add 1 to labels in order to form class-labels beginning from 0
(dolist (datum mnist-train) (incf (car datum)))
(dolist (datum mnist-test) (incf (car datum)))
(multiple-value-bind (datamat target)
(clol-dataset->datamatrix/target mnist-train)
(defparameter mnist-datamatrix datamat)
(defparameter mnist-target target))
(multiple-value-bind (datamat target)
(clol-dataset->datamatrix/target mnist-test)
(defparameter mnist-datamatrix-test datamat)
(defparameter mnist-target-test target)))
;; 並列化を有効化
(setf lparallel:*kernel* (lparallel:make-kernel 4))
;; cross-validation
(defparameter mnist-n-fold 5)
(cross-validation-forest-with-refine-learner
mnist-n-fold mnist-n-class mnist-dim mnist-datamatrix mnist-target
:n-tree 500 :bagging-ratio 0.1 :max-depth 10 :n-trial 28 :gamma 10d0 :min-region-samples 5)
これで5-fold cross-validationの平均値が出る。他を固定してn-treeとbagging-ratioを動かしてみると、
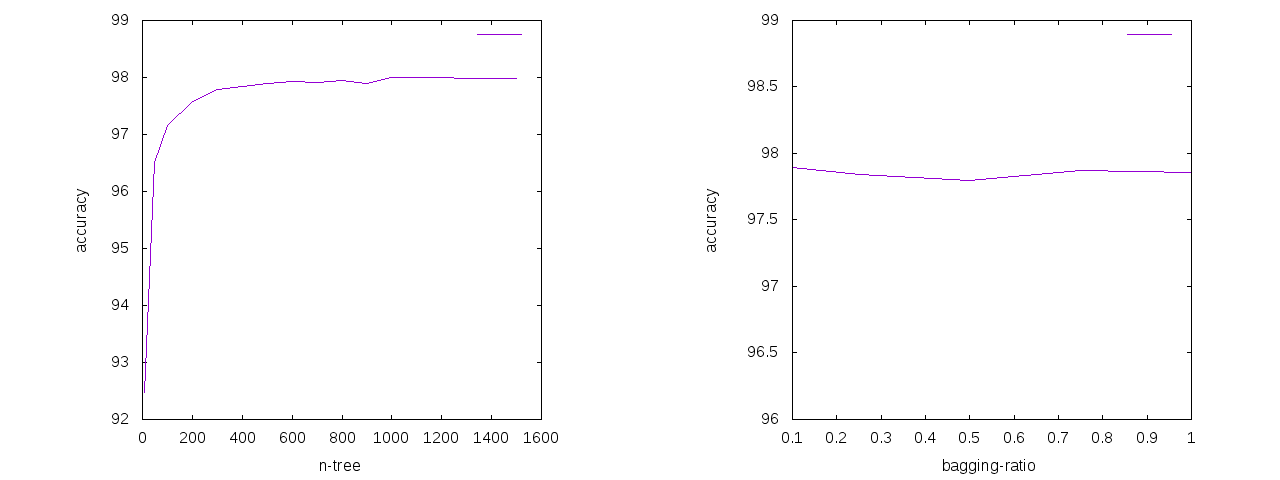 決定木の数n-treeは500くらい以上にしても正答率はほとんど変わらなくなる。論文の通りに、バギング比率bagging-ratioはほとんど正答率に影響を与えないことが分かるので、0.1などの小さい値にすることで計算時間を短縮できる。
決定木の数n-treeは500くらい以上にしても正答率はほとんど変わらなくなる。論文の通りに、バギング比率bagging-ratioはほとんど正答率に影響を与えないことが分かるので、0.1などの小さい値にすることで計算時間を短縮できる。
ランダムフォレストはあまりメタパラメータに敏感ではないので、割と何も考えずにデフォルト値でやってもうまくいく。逆に言うとあまりチューニングの余地はない。