LightGBMをCommon Lispから使う
インストール
LightGBMをソースからインストール
ホームディレクトリ直下に置くことに注意する。 最新のmasterを入れた(現時点でv3.3.5)。以下のようにして手元でビルドする。
cd ~/
git clone --recursive https://github.com/microsoft/LightGBM
cd LightGBM
mkdir build
cd build
cmake ..
make -j4
Common Lispバインディングをインストール
cl-autowrapを使っているため、libffiが必要。
roswellを使っている前提で、~/.roswell/local-projects 以下にgit cloneする。
最新のcommitでv3.3.2に対応したと書いてあったが最新のLightGBMでも動いた。
cd ~/.roswell/local-project
git clone git@common-lisp.net:cungil/lightgbm.git
SBCLからロードしてみる
quickloadでロードできる。 ここでライブラリが見つからない場合はlightgbm/wrapper.lispを見る。ホームディレクトリ直下にLightGBMディレクトリがあることを仮定しているようだった。
(ql:quickload :lightgbm)
テスト実行
テストは以下のようにすると実行できる。
;; テスト実行
(asdf:test-system :lightgbm/test)
#|
Running test suite LIGHTGBM-SUITE
Running test READ-DATA .
Running test EMPTY-DATASET .
Running test NUM-CLASSES .
Running test FEATURE-NAMES .
Running test FEATURE-NAMES-SET .
Running test FEATURE-NAMES-BOOSTER .
Running test UPDATE-PARAM-CHECK .
Running test BOOSTER-TO-STRING f
Running test DUMP-MODEL f
Running test EARLY-STOPPING
[0] train l2: 0.244602 train auc: 0.738768 valid-1 l2: 0.244076 valid-1 auc: 0.722112
[1] train l2: 0.240556 train auc: 0.780544 valid-1 l2: 0.240297 valid-1 auc: 0.773591
[2] train l2: 0.235815 train auc: 0.791324 valid-1 l2: 0.235733 valid-1 auc: 0.781387
[3] train l2: 0.231278 train auc: 0.795224 valid-1 l2: 0.231352 valid-1 auc: 0.785039
[4] train l2: 0.227683 train auc: 0.803645 valid-1 l2: 0.228939 valid-1 auc: 0.778678
[5] train l2: 0.224675 train auc: 0.808916 valid-1 l2: 0.225930 valid-1 auc: 0.790538
[6] train l2: 0.221149 train auc: 0.812187 valid-1 l2: 0.222515 valid-1 auc: 0.793174
[7] train l2: 0.217942 train auc: 0.814030 valid-1 l2: 0.219569 valid-1 auc: 0.793803
[8] train l2: 0.214806 train auc: 0.814784 valid-1 l2: 0.216800 valid-1 auc: 0.791699
[9] train l2: 0.211968 train auc: 0.814482 valid-1 l2: 0.214371 valid-1 auc: 0.790836
...
|#
データセット
ドキュメントとかはないようなので、テストファイルを読み解いて基本的な使い方を見ていく。
ファイルからデータをロード
訓練データをロードする
リポジトリに付属しているサンプルデータを読み込んでみる。
(defparameter src-dir (asdf:system-source-directory :lightgbm))
(defparameter train-data (lgbm:read-data-file (merge-pathnames "examples/binary.train" src-dir)))
; train-data => #<LIGHTGBM::LGBM-DATASET 7000x28 LABEL>
データファイルの冒頭はこうなっている。 タブ区切りのテキストファイルで先頭要素が教師信号になっている(この場合は二値分類なので1 or 0) データファイルはCSV, TSV, libsvmフォーマットが利用可能とのこと。
1 0.869 -0.635 0.226 0.327 -0.690 0.754 -0.249 -1.092 0.000 1.375 -0.654 0.930 1.107 1.139 -1.578 -1.047 0.000 0.658 -0.010 -0.046 3.102 1.354 0.980 0.978 0.920 0.722 0.989 0.877
1 0.908 0.329 0.359 1.498 -0.313 1.096 -0.558 -1.588 2.173 0.813 -0.214 1.271 2.215 0.500 -1.261 0.732 0.000 0.399 -1.139 -0.001 0.000 0.302 0.833 0.986 0.978 0.780 0.992 0.798
1 0.799 1.471 -1.636 0.454 0.426 1.105 1.282 1.382 0.000 0.852 1.541 -0.820 2.215 0.993 0.356 -0.209 2.548 1.257 1.129 0.900 0.000 0.910 1.108 0.986 0.951 0.803 0.866 0.780
0 1.344 -0.877 0.936 1.992 0.882 1.786 -1.647 -0.942 0.000 2.423 -0.676 0.736 2.215 1.299 -1.431 -0.365 0.000 0.745 -0.678 -1.360 0.000 0.947 1.029 0.999 0.728 0.869 1.027 0.958
...
lgbm:read-data-file の返値は LGBM-DATASET というクラスのオブジェクトだが、中身はポインタなのでCの構造体へのポインタなのだろう。
データセットに対するメソッド
;; データセットの形状
(lgbm:dims train-data) ; => (7000 28)
(lgbm:nrow train-data) ; => 7000
(lgbm:nfeatures train-data) ; => 28
;; 特徴名(ある場合)
(lgbm:feature-names train-data)
; ("Column_0" "Column_1" "Column_2" "Column_3" "Column_4" "Column_5" "Column_6"
; "Column_7" "Column_8" "Column_9" "Column_10" "Column_11" "Column_12"
; "Column_13" "Column_14" "Column_15" "Column_16" "Column_17" "Column_18"
; "Column_19" "Column_20" "Column_21" "Column_22" "Column_23" "Column_24"
; "Column_25" "Column_26" "Column_27")
;; fieldメソッドでデータセットの一部を取り出せる
;; 教師信号をリストとして取り出す
(lgbm:field train-data :label)
; => (1.0 1.0 1.0 0.0 ...)
テストデータをロードする
テストデータをロードする時には訓練データへの参照を入れる必要があることに注意。
(defparameter test-data
(lgbm:read-data-file (merge-pathnames "examples/binary.test" src-dir)
:reference train-data))
データセットからモデルを作り、訓練する
lgbm:boosterメソッドで訓練データを指定してモデルを作れる。
この時点では訓練されておらず、 lgbm:trainで訓練する。
(defparameter model (lgbm:booster train-data))
;; データを何周するかを指定して訓練する
(lgbm:train model 10)
#|
[0] train l2: 0.238643
[1] train l2: 0.229898
[2] train l2: 0.222344
[3] train l2: 0.215907
[4] train l2: 0.210251
[5] train l2: 0.205303
[6] train l2: 0.200922
[7] train l2: 0.197002
[8] train l2: 0.193583
[9] train l2: 0.190432
(("train" "l2" 0.2386427619778241d0 0.22989769815398528d0 0.22234391028374623d0
0.21590656551973061d0 0.21025111291736295d0 0.20530299011235634d0
0.20092151907590491d0 0.19700195198301462d0 0.1935828883937399d0
0.190431655495415d0))
|#
訓練時にテストデータを指定することでラウンド毎の損失関数の値を表示できる。
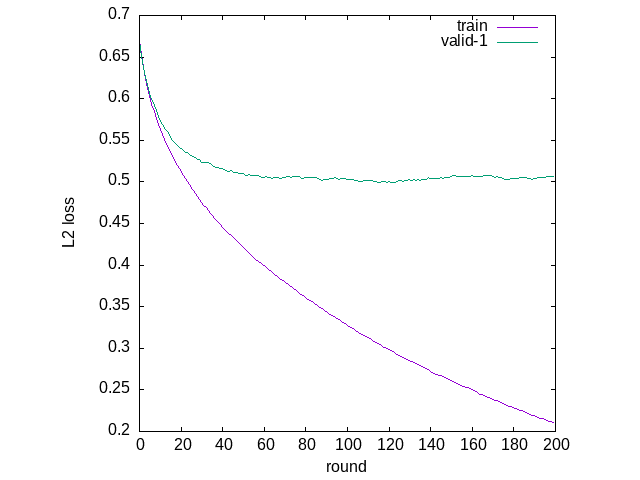
lgbm:trainの返値として損失関数の値の履歴が返るのでグラフ化してみると、訓練データにオーバーフィッティングしていることが分かる。
(defparameter train-result
(lgbm:train model 200 test-data))
;; [0] train binary_logloss: 0.670351 valid-1 binary_logloss: 0.668199
;; [1] train binary_logloss: 0.652719 valid-1 binary_logloss: 0.651034
;; [2] train binary_logloss: 0.637494 valid-1 binary_logloss: 0.637863
;; [3] train binary_logloss: 0.623994 valid-1 binary_logloss: 0.625398
;; [4] train binary_logloss: 0.612416 valid-1 binary_logloss: 0.615296
;; [5] train binary_logloss: 0.602115 valid-1 binary_logloss: 0.605989
;; ...
(ql:quickload :clgplot)
;; オーバーフィッティングしていることが分かる
(clgplot:plots (mapcar #'cddr train-result)
:title-list '("train" "valid-1")
:y-label "L2 loss"
:x-label "round")
early-stopping
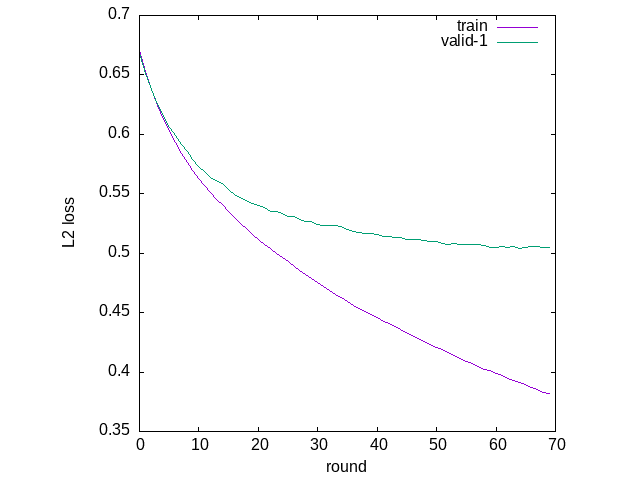
LightGBMのドキュメント によると、early-stopping-rounds で指定したラウンド毎にテストデータで性能向上が見られなければ終了する。
(defparameter train-result
(lgbm:train model 200
test-data ;; validation-sets
5 ;; early-stopping-rounds
))
;; オーバーフィッティングしていることが分かる
(clgplot:plots (mapcar #'cddr train-result)
:title-list '("train" "valid-1")
:y-label "L2 loss"
:x-label "round")
獲得したモデルから予測する
データファイルから予測し、結果もファイルに出力する場合。
(lgbm:predict-file model
(merge-pathnames "examples/binary.test" src-dir)
#P"/tmp/prediction-binary")
; => NIL
#|
$ head /tmp/prediction-binary -n 3
0.76719915412968998
0.41820078516584058
0.16528751293439295
|#
データファイルからCommon Lispの2次元配列を作り、そこから予測して結果をリストで受け取る場合。
(defparameter mat
(lgbm:read-data-file-as-matrix (merge-pathnames "examples/binary.test" src-dir)))
(lgbm:predict-matrix model mat :data-type :double :result-type 'double-float)
;; => ((0.76719915412969d0) (0.4182007851658406d0) (0.16528751293439295d0) ...)
モデルのファイルへの保存と復元
訓練などで変化したモデルオブジェクトをファイルに保存することができる。
ファイルの中身は通常のテキストファイルで、保存されたファイルからモデルを復元するには lgbm:booster に訓練データの代わりに保存されたモデルファイルを与えればよい。
;; save model
(lgbm:save model #P"/tmp/saved-model")
;; restore model
(defparameter restored-model
(lgbm:booster #P"/tmp/saved-model"))
後始末
モデルやデータセットはCの構造体。freeすることはできるか? 以下のようにすればおそらくできるが、2回実行すると処理系が落ちたりしたので安全なやり方を考える必要がありそう。
(cffi:foreign-free (slot-value model 'LIGHTGBM::POINTER))
MNISTでマルチクラス分類
ここまではリポジトリ付属のデータで試していたが、libsvmのサイトで配布されているMNIST(手書き数字)データで試してみようと思う。 このデータは行頭にラベルがあり、その後に特徴のインデックスとその特徴の値が交互に並んでいるような、疎なデータを記述するためのフォーマットで書かれている。 LightGBMはこのフォーマットに対応しているとのことなので、直接読み込ませてみた。
値が[0, 1]になるように正規化された訓練データ mnist.scale とテストデータ mnist.scale.tを用いる。
ちなみに先頭の1行は以下のようになっている。
$ head mnist.scale -n 1
5 153:0.0117647 154:0.0705882 155:0.0705882 156:0.0705882 157:0.494118 158:0.533333 159:0.686275 160:0.101961 161:0.65098 162:1 163:0.968627 164:0.498039 177:0.117647 178:0.141176 179:0.368627 180:0.603922 181:0.666667 182:0.992157 183:0.992157 184:0.992157 185:0.992157 186:0.992157 187:0.882353 188:0.67451 189:0.992157 190:0.94902 191:0.764706 192:0.25098 204:0.192157 205:0.933333 206:0.992157 207:0.992157 208:0.992157 209:0.992157 210:0.992157 211:0.992157 212:0.992157 213:0.992157 214:0.984314 215:0.364706 216:0.321569 217:0.321569 218:0.219608 219:0.152941 232:0.0705882 233:0.858824 234:0.992157 235:0.992157 236:0.992157 237:0.992157 238:0.992157 239:0.776471 240:0.713725 241:0.968627 242:0.945098 261:0.313725 262:0.611765 263:0.419608 264:0.992157 265:0.992157 266:0.803922 267:0.0431373 269:0.168627 270:0.603922 290:0.054902 291:0.00392157 292:0.603922 293:0.992157 294:0.352941 320:0.545098 321:0.992157 322:0.745098 323:0.00784314 348:0.0431373 349:0.745098 350:0.992157 351:0.27451 377:0.137255 378:0.945098 379:0.882353 380:0.627451 381:0.423529 382:0.00392157 406:0.317647 407:0.941176 408:0.992157 409:0.992157 410:0.466667 411:0.0980392 435:0.176471 436:0.729412 437:0.992157 438:0.992157 439:0.588235 440:0.105882 464:0.0627451 465:0.364706 466:0.988235 467:0.992157 468:0.733333 494:0.976471 495:0.992157 496:0.976471 497:0.25098 519:0.180392 520:0.509804 521:0.717647 522:0.992157 523:0.992157 524:0.811765 525:0.00784314 545:0.152941 546:0.580392 547:0.898039 548:0.992157 549:0.992157 550:0.992157 551:0.980392 552:0.713725 571:0.0941176 572:0.447059 573:0.866667 574:0.992157 575:0.992157 576:0.992157 577:0.992157 578:0.788235 579:0.305882 597:0.0901961 598:0.258824 599:0.835294 600:0.992157 601:0.992157 602:0.992157 603:0.992157 604:0.776471 605:0.317647 606:0.00784314 623:0.0705882 624:0.670588 625:0.858824 626:0.992157 627:0.992157 628:0.992157 629:0.992157 630:0.764706 631:0.313725 632:0.0352941 649:0.215686 650:0.67451 651:0.886275 652:0.992157 653:0.992157 654:0.992157 655:0.992157 656:0.956863 657:0.521569 658:0.0431373 677:0.533333 678:0.992157 679:0.992157 680:0.992157 681:0.831373 682:0.529412 683:0.517647 684:0.0627451
画像の四隅のように、データ全域で0になる特徴があるので、このままだと特徴数が訓練データとテストデータで異なると怒られる。
そのため全特徴にノイズを加えて非零にしたデータを末尾に1つ加えて、それぞれmnist.scale.full-feature, mnist.scale.t.full-featureとして保存しておく。
(ql:quickload :cl-libsvm-format)
(defun make-full-feature-datum-from-first-of-dataset (dataset-path &key (stream t))
(let* ((dataset (svmformat:parse-file dataset-path))
(label (caar dataset))
(datum (cdar dataset)))
(format stream "~A" label)
(loop for i from 1 to 784
do (format stream " ~A:~A" i (or (getf datum i) (random 0.1))))
(format stream "~%")))
;; $ cp mnist.scale mnist.scale.full-feature
;; $ cp mnist.scale.t mnist.scale.t.full-feature
(with-open-file (out #P"/home/wiz/datasets/mnist.scale.full-feature"
:direction :output :if-exists :append)
(make-full-feature-datum-from-first-of-dataset #P"/home/wiz/datasets/mnist.scale" :stream out))
(with-open-file (out #P"/home/wiz/datasets/mnist.scale.t.full-feature"
:direction :output :if-exists :append)
(make-full-feature-datum-from-first-of-dataset #P"/home/wiz/datasets/mnist.scale.t" :stream out))
次に、データをLightGBMに読み込ませてみる。
(defparameter mnist-train
(lgbm:read-data-file #P"/home/wiz/datasets/mnist.scale.full-feature"))
(lgbm:dims mnist-train) ; => (60001 785)
(defparameter mnist-test
(lgbm:read-data-file #P"/home/wiz/datasets/mnist.scale.t.full-feature"
:reference mnist-train))
(lgbm:dims mnist-test) ; => (10001 785)
次にモデルを作るが、モデルパラメータとしてマルチクラス分類であることを伝える必要があることに注意。 デフォルトではデータのラベルに数字が来る場合はregressionになってしまうようで、予測結果が実数になってしまった。 LightGBMのパラメータについてはこちらを参照。
モデルパラメータは lgbm:booster でモデルを作るときに第二引数で属性リストで指定する。MNISTは10クラスの分類問題であるため num-classには10を指定する。
(defparameter mnist-model
(lgbm:booster mnist-train
'(:task "train"
:boosting-type "gbdt"
:objective "multiclass"
:metric "multi_logloss"
:num-class 10)))
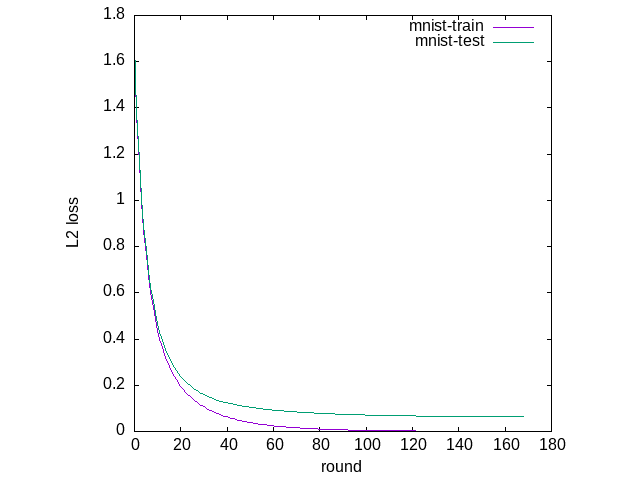
次にモデルを訓練する。
(defparameter mnist-train-result
(lgbm:train mnist-model 1000
mnist-test ;; validation-sets
5 ;; early-stopping-rounds
))
(clgplot:plots (mapcar #'cddr mnist-train-result)
:title-list '("mnist-train" "mnist-test")
:y-label "L2 loss"
:x-label "round")
予測時には密ではないデータをそのまま与えるとエラーになってしまう。
(lgbm:predict-file mnist-model
#P"/home/wiz/datasets/mnist.scale.t.full-feature"
#P"/tmp/predict-result")
;; The number of features in data (777) is not the same as it was in training data (785).
;; You can set ``predict_disable_shape_check=true`` to discard this error, but please be aware what you are doing.
疎なデータを扱うには予測パラメータとして predict_disable_shape_check=true を指定する必要がある。
(lgbm:predict-file mnist-model
#P"/home/wiz/datasets/mnist.scale.t.full-feature"
#P"/tmp/predict-result"
:parameters (lgbm::parameters-string '(:predict-disable-shape-check "true")))
こうしてできた予測結果のファイルを見てみると、0から9までの各クラスの所属確率の分布が出ていることが分かる。 テストデータの先頭要素のラベルは7なので、8番目の位置の所属確率が最大になっていることと一致している。
$ head /tmp/predict-result -n 1
1.3661222242181682e-08 3.5541992554735498e-09 1.5271590448922296e-07 1.9146910950631125e-06 6.5305270234432119e-08 1.2101950613649194e-07 2.8246822041150297e-09 0.99999553007195019 8.5283260930134873e-08 2.1108729091782681e-06
次にLispの配列から予測を立ててみる。
libsvm形式のデータから、教師信号を行の先頭要素に持つ密な行列を作る。
(defmacro do-index-value-list ((index value list) &body body)
(let ((iter (gensym))
(inner-list (gensym)))
`(labels ((,iter (,inner-list)
(when ,inner-list
(let ((,index (car ,inner-list))
(,value (cadr ,inner-list)))
,@body)
(,iter (cddr ,inner-list)))))
(,iter ,list))))
;; 教師信号を行の先頭要素に持つ行列
(defun read-as-datamatrix (data-path data-dimension)
(let* ((data-list (svmformat:parse-file data-path))
(len (length data-list))
(datamatrix (make-array (list len (1+ data-dimension))
:element-type 'double-float
:initial-element 0d0)))
(loop for i from 0
for datum in data-list
do (setf (aref datamatrix i 0) (coerce (car datum) 'double-float))
(do-index-value-list (j v (cdr datum))
(setf (aref datamatrix i j) (coerce v 'double-float))))
datamatrix))
(defparameter test-datamatrix (read-as-datamatrix #P"/home/wiz/datasets/mnist.scale.t" 784))
(array-dimensions test-datamatrix) ; => (10000 785)
このテストデータ行列に対して lgbm:predict-matrix を呼び出すと、ファイルに対して予測を立てたときと同じ分布のリストのリストとして得られる。
(defparameter prediction-result
(lgbm:predict-matrix mnist-model
test-datamatrix
:data-type :double :result-type 'double-float))
;; ((2.0607093963303992d-8 3.44975123289346d-9 2.9490942329303693d-7
;; 4.275286585519134d-6 5.687496008073154d-8 6.733259931695642d-8
;; 3.859072491234042d-9 0.9999931904935438d0 6.232959724321938d-8
;; 2.024857373099657d-6)
;; ...)
最大の確率を持つクラスを各テストデータに対して計算して、実際のテストデータのラベルと比較して正答率を出してみる。
(defun max-position (lst)
(let ((max-value (apply #'max lst)))
(position-if (lambda (x)
(= x max-value)) lst)))
(defparameter prediction-result-class
(mapcar #'max-position prediction-result))
(defparameter test-datamatrix-class
(loop for i from 0 below (array-dimension test-datamatrix 0)
collect (floor (aref test-datamatrix i 0))))
(loop for predicted in prediction-result-class
for target in test-datamatrix-class
count (= predicted target))
;; => 9809
98.09%という結果になった。特に調整してないにしては、かなりいい数字が出ている。