cl-random-forest: Common Lispで高性能なランダムフォレストを実装した
はじめに
前の記事でCLMLのランダムフォレストを試したのだが、計算速度が遅くてとても実用レベルとは言えなかったので一から書き直すことにした。また先月のShibuya.lispのLispmeetupでも発表してきた。何をやっているかはこの発表のスライドで大体説明しているのだが、実際の使い方はデモでしか説明していなかったのでこの記事で説明する。
単純なランダムフォレストの構築ではCLMLの実装よりも50~60倍程度速くなっている。上記スライドにもベンチマークがあるが、RのRangerやPythonのscikit-learnなどの実装と比べても速く、精度も良い。
実装にあたって参考にしたのは、PRMLの14章とかこのへんのスライド
ランダムフォレストは分類だけでなく回帰にも使えるのだが、今のところ実装してるのは分類だけ。
論文: Global Refinement of Random Forest
単に普通のランダムフォレストを実装するだけでは面白くないので、加えて次の論文のアルゴリズムを実装している。
この手法は、学習済みのランダムフォレスト全体の構造を使って元のデータを高次元かつ疎なデータに変換する。そしてその疎なデータを線形分類器で再学習することによってより速く、より良い精度を出すというものだ。言い換えると、ランダムフォレストを非線形な特徴抽出器として使って線形分類器の入力を作っている。
更に、学習した線形分類器のパラメータ(重み)を使って寄与度の小さい枝を削除する枝刈りをすることもできる。そうすることによって最終的な予測精度をほとんど落とさずにモデルのサイズを大幅に縮小することができる。
この手法の再学習と枝刈りはランダムフォレスト内の決定木全体の情報を使って行なわれる。そのため、単純に各決定木の予測を平均化していた従来のランダムフォレストに対して、より相互補完的な予測の統合ができる。枝刈りに関しても、従来は個々の決定木ごとの情報量基準に従って枝刈りしていたが、この手法では森全体の中での重要度に応じて枝刈りするため、より効果が高い。
また、従来のランダムフォレストではバギング比率や分割の試行回数を減らすと性能が悪化してしまっていたが、この手法ではほとんど悪化しない(上記論文のFigure 3)。
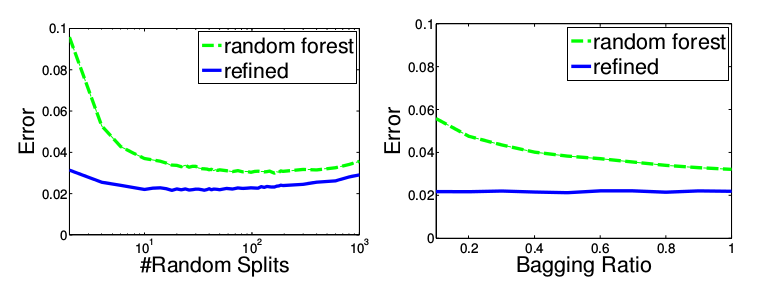
バギングに使うデータサイズを小さくすることができ、分割の試行回数も少なくできるということは、ランダムフォレストの構築にかかる時間を大幅に短縮できるということだ。そのためランダムフォレストの構築後に線形分類器の学習を行なったとしても、全体としての計算時間はむしろ短縮になる。
線形分類器は元論文ではLIBLINEARの線形SVMを使っているのだが、今回は前に実装したcl-online-learningのAROWを使う。その影響か元論文よりも若干の精度向上が見られた。
インストール
まだQuicklispに登録されていないので、local-projects以下に置くか、Roswellからインストールする。
ros install masatoi/cl-random-forest
最新のcl-online-learningが必要なので、Quicklispを最新の状態にするか、以下のように明示的にgithubから最新版をインストールするかする。
ros install masatoi/cl-online-learning masatoi/cl-random-forest
ランダムフォレストには少なからずメモリを使うので、処理系の起動オプションで動的に確保できるメモリ空間の最大値を大きめに取っておく。例えばSBCLに最大4GBのメモリを当てるには次のようにする。
sbcl --dynamic-space-size=4096
roswellの場合は
ros -Q dynamic-space-size=4096 run
使い方
データの用意
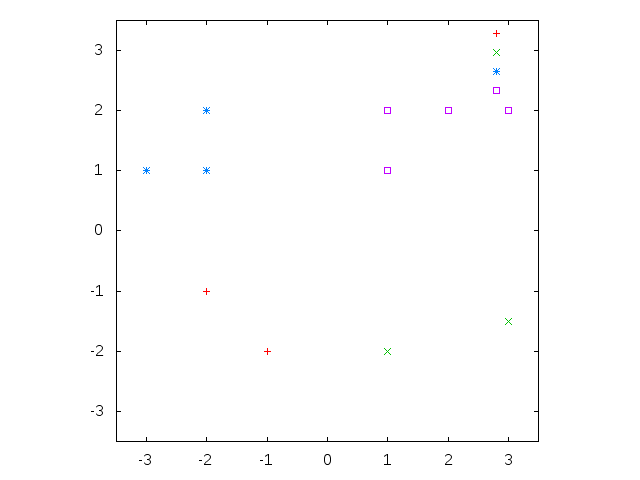
データセットは教師信号を表わす一次元fixnum配列と、データ本体を表わす二次元double-float配列からなる。このデータ行列における行が一つのデータに対応する。例えば、以下の図のような2次元4クラスのデータであれば、データセットのフォーマットはこうなる。教師信号(クラスID)は0スタートの整数であることに注意する。
(defparameter *target*
(make-array 11 :element-type 'fixnum
:initial-contents '(0 0 1 1 2 2 2 3 3 3 3)))
(defparameter *datamatrix*
(make-array '(11 2)
:element-type 'double-float
:initial-contents '((-1.0d0 -2.0d0)
(-2.0d0 -1.0d0)
(1.0d0 -2.0d0)
(3.0d0 -1.5d0)
(-2.0d0 2.0d0)
(-3.0d0 1.0d0)
(-2.0d0 1.0d0)
(3.0d0 2.0d0)
(2.0d0 2.0d0)
(1.0d0 2.0d0)
(1.0d0 1.0d0))))
決定木を作る
まずデータセットから一本の決定木を作ってみる。
(defparameter *n-class* 4) ; クラス数
(defparameter *n-dim* 2) ; 特徴次元数
;; 決定木の構築(学習)
;; キーワードオプションは全部デフォルト値
(defparameter *dtree*
(clrf:make-dtree *n-class* *n-dim* *datamatrix* *target*
:max-depth 5 ; 決定木の最大深さ
:min-region-samples 1 ; 領域内の最小サンプル数、これを下回ったら分岐をやめる
:n-trial 10)) ; 分岐の試行回数
;; 予測: *datamatrix*の最初のデータを予測する
(clrf:predict-dtree *dtree* *datamatrix* 0) ; => 0
;; テスト
(clrf:test-dtree *dtree* *datamatrix* *target*)
; Accuracy: 100.0%, Correct: 11, Total: 11
; => 100.0, 11, 11
決定木は単なる構造体で、make-dtree関数で構築できる(決定木を構築した時点で学習は終わっている)。次に、predict-dtree関数で訓練に使ったデータセットの最初の行を入力にして、予測されるクラス番号を返している。この例では0が返っているが、*target*の最初の要素も0なので正解していることになる。データセット全体に対するテストはtest-dtree関数で行う。これは正答率、正答数、テストデータの数を多値で返す。
ランダムフォレストを作る
次に決定木の集合体であるランダムフォレストを作ってみる。
;; ランダムフォレストの構築
(defparameter *forest*
(clrf:make-forest *n-class* *n-dim* *datamatrix* *target*
:n-tree 10 ; 決定木の数
:bagging-ratio 1.0 ; 元のデータに対してバギングで使うデータの比率
:max-depth 5
:min-region-samples 1
:n-trial 10))
;; 予測、テスト
(clrf:predict-forest *forest* *datamatrix* 0) ; => 0
(clrf:test-forest *forest* *datamatrix* *target*)
; Accuracy: 100.0%, Correct: 11, Total: 11
; => 100.0, 11, 11
ランダムフォレストも構造体で、内部に決定木のリストを持っている。ランダムフォレストはmake-forest関数で構築できる。キーワードオプションは決定木とほぼ同じだが、決定木の数n-treeとバギング比率bagging-ratioを指定するところが異なる。
バギングとは元のデータセットからブートストラップサンプリング(重複を許すランダムサンプリング)して小さなデータセットを決定木ごとに作り、それを使って各決定木を学習することをいう。バギングによって決定木の多様性が増すことによって全体としての頑健性が増す。
決定木と同様に、予測・テストにはそれぞれpredict-forest関数、test-forest関数を使う。
Global refinement
ここまでは通常のランダムフォレストの話だったが、ここからランダムフォレスト全体の情報を使っての再学習の話になる。
まずは、構築したランダムフォレストを使って、元のデータセットを線形分類器への入力となるデータセットに変換する。具体的には、入力データが決定木のどの葉ノードに分類されるか調べ、実際に分類される葉を1、それ以外の葉を0とする。これを各決定木について行ない、それを一列に並べたものが変換後のデータとなる。
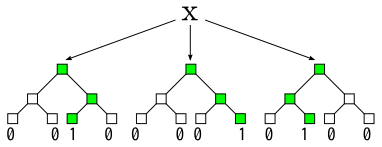
この新しいデータセットはランダムフォレスト中の全決定木の葉の総数が特徴数になる非常に高次元のデータだが、実際に値が入るのは各決定木につき1つだけであり、疎なデータになる。従って、各データについて値が入っているところのインデックスだけをテーブルに保持しておけばいい。これにはmake-refine-datasetを使う。
(defparameter *forest-refine-dataset* (clrf:make-refine-dataset *forest* *datamatrix*))
;; テーブルのサイズはデータ数×決定木の数
;; #(#(3 5 11 15 19 23 26 30 33 39)
;; #(3 7 11 15 19 23 26 30 35 39)
;; #(2 5 9 14 17 22 25 28 32 37)
;; #(2 4 9 14 16 22 25 28 31 37)
;; #(1 6 10 13 18 20 26 29 34 38)
;; #(1 6 10 13 18 21 26 29 34 38)
;; #(1 6 10 13 18 21 26 29 34 38)
;; #(0 4 8 12 16 20 24 27 31 36)
;; #(0 4 8 12 17 20 24 27 31 36)
;; #(0 4 8 12 17 20 24 27 32 36)
;; #(0 4 8 12 17 21 25 27 32 36))
次に、このデータセットから線形分類器を学習する。make-refine-learner関数で線形分類器のオブジェクトを作り、train-refine-learner関数で訓練し、test-refine-learner関数でテストする。この簡単な例では学習データとテストデータを分けていないが、実際にはテストデータも変換する必要があることに注意する。
データによっては学習が収束するまでにはtrain-refine-learnerを数回呼ぶ必要があるかもしれない。簡単な収束判定を実装したものがtrain-refine-learner-process関数で、テストデータに対する精度で収束を判定するので訓練データと一緒にテストデータも与える必要がある。
(defparameter *forest-refine-learner* (clrf:make-refine-learner *forest*))
(clrf:train-refine-learner *forest-refine-learner* *forest-refine-dataset* *target*)
(clrf:test-refine-learner *forest-refine-learner* *forest-refine-dataset* *target*)
;; Accuracy: 100.0%, Correct: 11, Total: 11
;; 収束判定付き訓練
(clrf:train-refine-learner-process
*forest-refine-learner*
*forest-refine-dataset* *target* ; 訓練データ
*forest-refine-dataset* *target*) ; テストデータ
データ1つを予測したい場合は次のようにする。
(clrf:predict-refine-learner *forest* *forest-refine-learner* *datamatrix* 0)
Global pruning
さて、Global refinementの学習結果を利用して、重要度の小さい葉ノードを刈り込むことができる(pruning)。例えば、あるランダムフォレストから全体の10%の葉ノードを削除したい場合は以下のようにする。
;; ランダムフォレストを破壊的に枝刈り
(clrf:pruning! *forest* *forest-refine-learner* 0.1)
;; 線形分類器を再学習
(setf *forest-refine-dataset* (clrf:make-refine-dataset *forest* *datamatrix*))
(setf *forest-refine-learner* (clrf:make-refine-learner *forest*))
(clrf:train-refine-learner *forest-refine-learner* *forest-refine-dataset* *target*)
(clrf:test-refine-learner *forest-refine-learner* *forest-refine-dataset* *target*)
pruning!関数を呼ぶことで*forest*が破壊的に変更される。枝刈りした後は線形分類器の再学習が必要になる。このランダムフォレストの枝刈り→線形分類器の再学習を繰り返していくことで、モデルがコンパクトになっていく。
並列化
ランダムフォレストの中の決定木は互いに独立しているので、簡単に並列化することができ、その並列化粒度も大きい。ランダムフォレストの構築make-forest、Global refinement用データへの変換make-refine-datasetは並列化することによってかなりの高速化が期待できる。
またマルチクラス分類の場合、Global refinement時の線形分類器は二値分類器をクラス数だけ用意して学習することになる。この二値分類器のセットも独立した計算なので並列化することができる。train-refine-learner、test-refine-learner、train-refine-learner-processは並列化が効く。
並列化を有効化するには、lparallelのカーネル数を指定してやる必要がある。例えば自分の環境は4コアCPUなので、次のようにする。
;; 並列化有効化
(setf lparallel:*kernel* (lparallel:make-kernel 4))
;; 無効化
(setf lparallel:*kernel* nil)
今のところSBCL以外だと並列化はちゃんと動かないかも。
MNISTの例
もうちょっと実際的な例として、MNISTでやってみた例がここにある。
やっていることは上記の単純なデータでやっていることとほぼ同じで、テストデータに対して98.3%くらい出る。
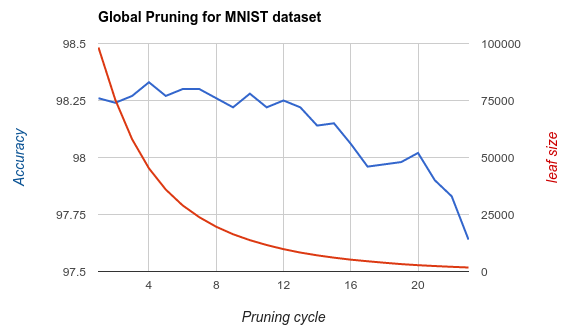
次の図はMNISTでGlobal pruningをやってみた結果で、枝刈り回数に対する精度と葉ノード数を表している。葉ノード数が当初の1/10くらいになっても精度はあまり変わらないことが分かる。
ベンチマーク
有名なランダムフォレストの実装と比較してみる。比較に使ったのはPythonのパッケージscikit-learnとRのパッケージranger。それぞれ本体部分はCythonとC++で実装されていて、並列化にも対応しており、速いとされている。
推奨設定での精度と所要時間
- scikit-learn: n-tree=100、他はデフォルト
- ranger: 全部デフォルト
- cl-random-forest: n-tree=500, bagging-ratio=0.1, max-depth=15, n-trial=特徴数の平方根
cl-random-forestはランダムフォレストの構築とGlobal refinementまでを行なう(枝刈りはしない)。
データはLIBSVMのサイトにあるデータセットを使う。
| #Train | #Test | #Feature | #Classes | |
|---|---|---|---|---|
| MNIST | 60000 | 10000 | 784 | 10 |
| letter | 15000 | 5000 | 16 | 26 |
| covtype | 348607 | 232405 | 54 | 7 |
| usps | 7291 | 2007 | 256 | 10 |
covtypeは訓練データとテストデータが分かれていないので、全体をシャッフルしてから上の表にあるデータ数で分割した。
結果は以下の表のようになる。ほとんどの場合でcl-random-forestの方が速く、精度も良いことが分かった。
| scikit-learn | ranger | cl-random-forest | |
|---|---|---|---|
| MNIST | 96.95%, 41.72sec | 97.17%, 69.34sec | 98.29%, 12.68sec |
| letter | 96.38%, 2.569sec | 96.42%, 1.828sec | 97.32%, 3.497sec |
| covtype | 94.89%, 263.7sec | 83.95%, 139.0sec | 96.01%, 103.9sec |
| usps | 93,47%, 3.583sec | 93.57%, 11.70sec | 94.96%, 0.686sec |
まとめ
- Common Lispでランダムフォレストの実装cl-random-forestをつくった
- 論文「Global Refinement of Random Forest」のアルゴリズムを実装した
- 有名なランダムフォレストの実装と比較した。速度でも精度でも勝っている
- TODO
- 回帰バージョンの実装
- 最近出てきたdeep forestの実装
- Deep Forest: Towards An Alternative to Deep Neural Networks
- 和訳: Deep Forest :Deep Neural Networkの代替へ向けて
- Global refinementではランダムフォレストと線形モデルを二段重ねにしていたが、deep forestではランダムフォレストをスタック化する+CNNのプーリングっぽい前処理をすることによりMNISTで99%越えを達成している